In this article, we'll explore how companies are transitioning from ETL to ELT and why "shift-left" is becoming a key trend in modern data architecture. From optimizing data processing workflows to reducing costs and latency, shift-left ensures high-quality data right from the source, ready for real-time analysis and decision-making.
1. From ETL to ELT
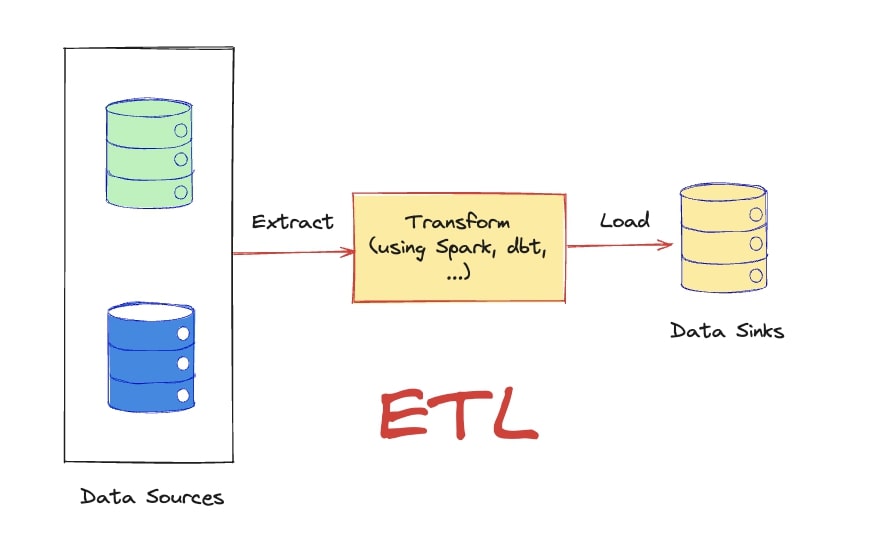
ETL (Extract, Transform, Load) is a widely used data processing workflow for moving data from various sources into a target data warehouse or database, where it can be analyzed and effectively utilized. This process includes three main steps:
- Extract: Collect data from multiple sources, regardless of format, to prepare for further processing.
- Transform: Clean and standardize the data, applying business rules to ensure consistency and relevance for analysis.
- Load: Store the transformed data in the target warehouse, ready for analysis and use.
 Click to zoom
Click to zoom
Problems with ETL:
- Time and Resource Intensive: The transformation phase occurs before loading, requiring heavy compute resources and extending processing times—especially with large data volumes.
- Scalability and Flexibility Issues: Traditional ETL doesn’t scale well as data grows, and pre-load transformations limit flexibility when analytics needs change frequently.
- High Complexity: ETL pipelines are complex to build and maintain, prone to errors, and rigid in execution order (extract → transform → load).
- Doesn’t Leverage Cloud Power Effectively: Modern cloud data warehouses are highly scalable, but traditional ETL fails to fully utilize this due to pre-load transformations.
 Click to zoom
Click to zoom
The Emergence of ELT:
- To address ETL's limitations, the ELT (Extract, Load, Transform) approach was introduced. ELT reverses the order: data is extracted and loaded directly into the data warehouse first, and transformations are performed afterward within the destination. This leverages the powerful processing capabilities of cloud platforms (e.g., BigQuery, Snowflake, or Redshift) for faster and more efficient data transformations.
- With ELT, raw data can be ingested immediately, allowing flexible, on-demand transformation based on analytical needs. ELT not only reduces cost and processing time but also scales better with growing data volumes—ideal for modern applications that demand high-throughput, complex data handling. However…
2. When ELT Is Too Easy, It Comes With Trade-Offs
As data grows in volume, velocity, and variety, companies are increasingly adopting ELT—moving data to the cloud and processing it conveniently. But when this process becomes too fast and uncontrolled, it can lead to "data swamp" — massive, unstructured, and low-value datasets. This drives up costs without delivering proportional value. A more critical issue arises when data loaded into storage systems is accessed by multiple teams, often resulting in repeated cleaning or transformation efforts. Additionally, the "reverse ETL" process (pushing data back into operational systems) can complicate data flows, increase latency, and make maintenance harder.

3. Time to "Shift-Left"
The shift-left architecture addresses ELT’s challenges by moving data processing and governance closer to the source systems. This ensures that data is processed accurately at the origin—once—and reused consistently across downstream systems. So how do we process data right as it's created? The answer is stream processing, with a workflow like this:
- Connect directly to the data stream.
- Use a data contract to clean and validate data quality from the source.
- Data engineers write transformation logic on the stream, preparing it for downstream systems.
Note: A data contract is an agreement between data producers and data consumers, defining structure and quality expectations. It includes schema, metadata, encoding rules, and versioning policies to minimize impact on downstream systems.
Besides reducing latency and duplicated data processing, shift-left ensures fresher, more reliable data and helps control storage costs in cloud warehouses or other storage systems.Click to zoom

4. Netflix Uses "Shift-Left" Too
The shift-left approach is increasingly adopted by major tech companies like Netflix. With over 450 million events daily from 100+ million users across 190 countries, Netflix uses shift-left to optimize data processing. Instead of running batch jobs that take up to 8 hours, they now deliver real-time recommendations based on immediate user activity.
5. Conclusion
Shift-left is becoming a strategic solution in modern data management, enabling fast, accurate, and efficient processing at the earliest stages. By pushing data quality and transformation upstream, it reduces costs and latency while ensuring data readiness for real-time analytics and decision-making. As data becomes more dynamic and diverse, shift-left is a critical step to maintain competitive advantage, optimize infrastructure, and support real-time needs.
If you'd like to learn more about modern data architectures, practical implementation at scale, and how to optimize your data systems, don’t forget to sign up for FSDS's MLOps and Data Engineer courses.
6. References
- Shifting Left: Discover What's Possible When You Process Data Closer to the Source
- The Shift Left Architecture – From Batch and Lakehouse to Real-Time Data Products with Data Streaming
- What is Shift Left?
- Apache Kafka + Flink + Snowflake: Cost Efficient Analytics and Data Governance
- Data Contracts for Schema Registry on Confluent Platform