Rate Limiting in FastAPI: Essential Protection for ML API Endpoints
What is Rate Limiting?
Rate limiting is a mechanism to control how many requests a client can make to your API within a specific timeframe. It acts as a gatekeeper, preventing abuse, ensuring fair resource distribution, and protecting your infrastructure from overload. For ML APIs, where inference tasks can be computationally expensive, rate limiting becomes critical to maintain stability and cost efficiency.
Installation Requirements
Before starting, ensure you have Python installed (I tested with Python 3.9.12), then install the required dependencies for each approach:
- Base requirements (all examples):
1pip install fastapi==0.115.10 uvicorn==0.34.0
- For Redis-based rate limiting (Approach 2):
1pip install fastapi-limiter==0.1.6 aioredis==2.0.1
- For
slowapirate limiting (Approach 3):
1pip install slowapi==0.1.9
Why Rate Limiting Matters for ML Engineers
Machine learning endpoints often require significant computational resources. Consider these scenarios where rate limiting becomes critical:
- Preventing resource exhaustion: ML inference, especially for large models, can consume substantial CPU/GPU resources
- Protecting against abuse: Without limits, a single client could monopolize your service
- Managing costs: For cloud-deployed models, each prediction may have associated costs
- Ensuring fair service: Distributing resources fairly across all clients
- Stabilizing performance: Preventing traffic spikes that could impact model serving latency Unlike traditional web applications, ML endpoints might perform complex operations involving large models loaded in memory. A sudden influx of requests could lead to out-of-memory errors, degraded performance, or even service outages.
Implementation Options for Rate Limiting in FastAPI
FastAPI doesn't include built-in rate limiting, but several approaches are available. Let's explore them in order of complexity and features.
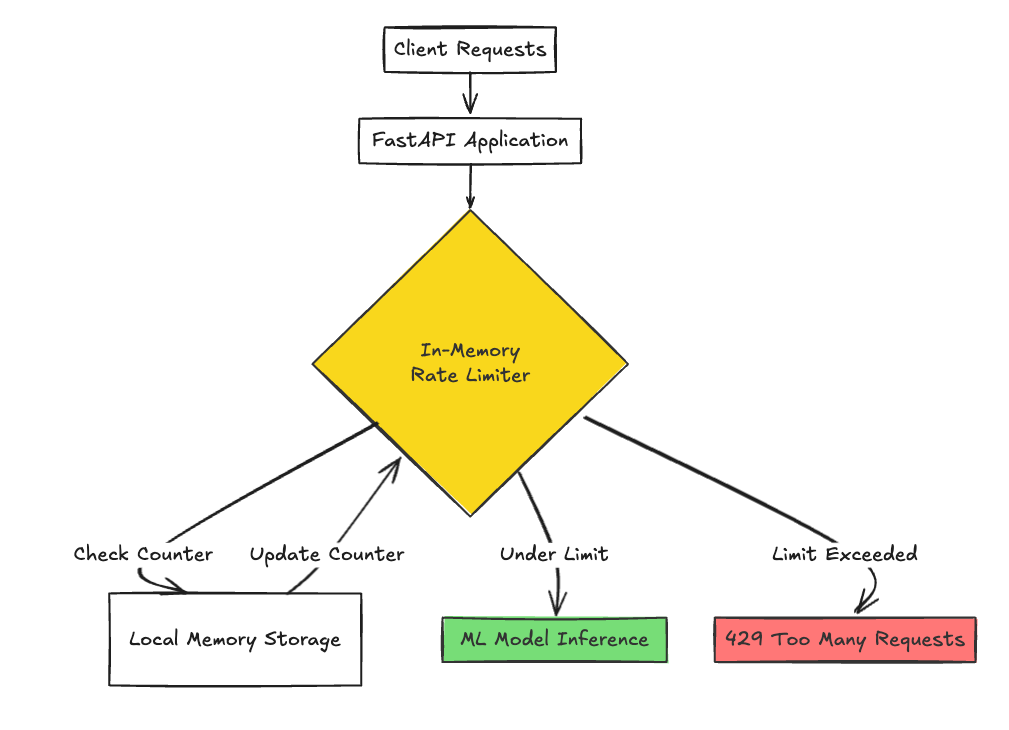
Approach 1: In-Memory Rate Limiting (No External Dependencies)
This approach is ideal for development environments, single-server deployments, or when you're just starting to implement rate limiting. It's perfect when you need something quick to implement without adding infrastructure complexity.
1from fastapi import FastAPI, Request, HTTPException, Depends 2import time 3app = FastAPI() 4# In-memory storage for request counters 5request_counters = {} 6class RateLimiter: 7 def __init__(self, requests_limit: int, time_window: int): 8 self.requests_limit = requests_limit 9 self.time_window = time_window 10 def __call__(self, request: Request): 11 client_ip = request.client.host 12 route_path = request.url.path 13 current_time = int(time.time()) 14 key = f"{client_ip}:{route_path}" 15 if key not in request_counters: 16 request_counters[key] = {"timestamp": current_time, "count": 1} 17 else: 18 if current_time - request_counters[key]["timestamp"] > self.time_window: 19 request_counters[key] = {"timestamp": current_time, "count": 1} 20 elif request_counters[key]["count"] >= self.requests_limit: 21 raise HTTPException(status_code=429, detail="Too Many Requests") 22 else: 23 request_counters[key]["count"] += 1 24 # Clean up expired entries 25 for k in list(request_counters.keys()): 26 if current_time - request_counters[k]["timestamp"] > self.time_window: 27 request_counters.pop(k) 28 return True 29@app.post("/predict", dependencies=[Depends(RateLimiter(requests_limit=10, time_window=60))]) 30def predict_endpoint(data: dict): 31 return {"prediction": 0.95, "confidence": 0.87} 32@app.post("/batch-predict", dependencies=[Depends(RateLimiter(requests_limit=2, time_window=60))]) 33def batch_predict_endpoint(data: dict): 34 return {"results": [{"prediction": 0.95}, {"prediction": 0.85}]} 35@app.get("/model-info") 36def model_info(): 37 return {"model_version": "v1.2.3", "framework": "PyTorch"} 38if __name__ == "__main__": 39 import uvicorn 40 uvicorn.run(app, host="0.0.0.0", port=8000)
This implementation tracks requests by client IP and endpoint path. For each request, it checks if the client has exceeded their limit within the defined time window. How to Run:
- Save as
app.py. - Run:
1uvicorn app:app --host 0.0.0.0 --port 8000
How to Test:
- With
curl:
1for i in {1..11}; do curl -X POST http://localhost:8000/predict -H "Content-Type: application/json" -d '{"data": [1,2,3]}'; echo ""; done
- After 10 requests, you’ll get a "429 Too Many Requests" response. Pros:
- No external dependencies.
- Easy to implement.
- Endpoint-specific limits. Cons:
- Not suitable for distributed systems.
- Memory usage scales with clients.
Approach 2: Redis-Based Rate Limiting with fastapi-limiter (With Docker)
For production-level applications, using a caching layer like Redis provides a scalable and persistent solution:
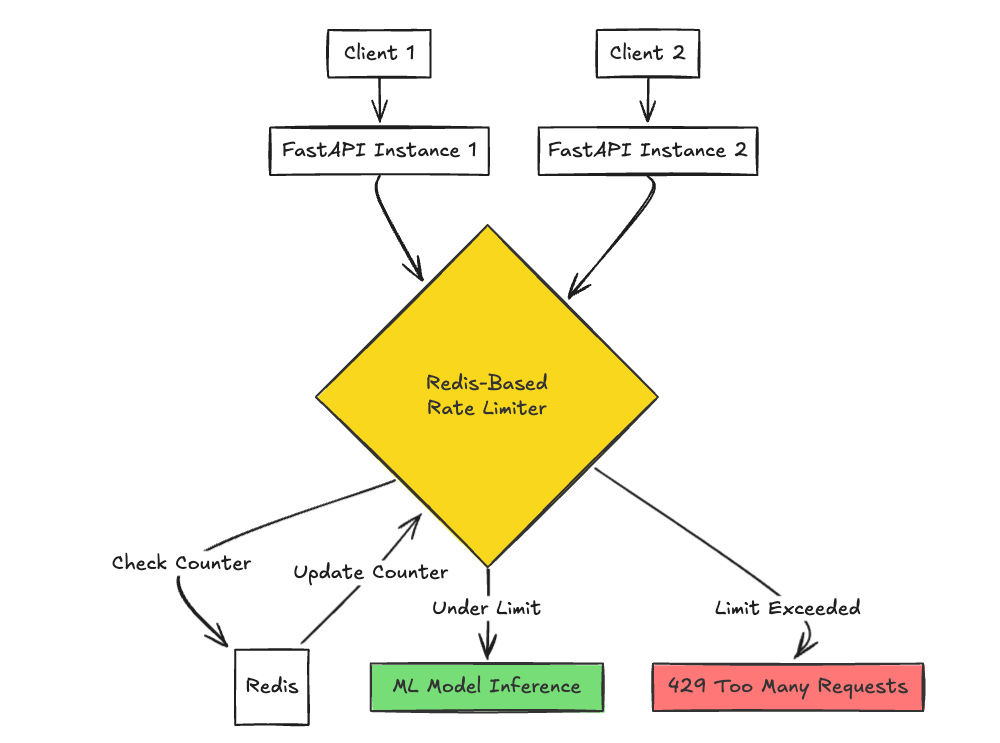
- Supports distributed rate limiting across multiple app instances.
- Persists rate limit counters across restarts (with Redis persistence enabled).
- Scalable with minimal performance overhead.
- Well-maintained library with good documentation. Cons
- Requires Redis infrastructure, adding setup complexity.
- Introduces an additional dependency to manage.
Step-by-Step Setup with Docker:
Install Docker: Ensure Docker is installed on your machine. Download it from Docker’s official site and follow the installation instructions for your operating system (Windows, macOS, or Linux). Pull the Redis Docker Image Use the official Redis image from Docker Hub:
1docker pull redis
This ensures you’re using a stable, well-maintained version of Redis. Run Redis in a Docker Container Start a Redis container with the following command:
1docker run -d --name redis-server -p 6379:6379 redis
-d: Runs the container in detached mode (background).--name redis-server: Names the container for easy reference.-p 6379:6379: Maps port 6379 on your host to port 6379 in the container (Redis’s default port). Redis will now be accessible atlocalhost:6379on your host machine. Verify Redis Is Running Confirm the container is active:
1docker ps
You should see redis-server in the output.
Optionally, test the Redis instance by connecting to it:
1docker exec -it redis-server redis-cli
In the Redis CLI, type PING. If Redis responds with PONG, it’s running correctly.
Set Up and test the FastAPI Application
The fastapi-limiter package integrates with Redis to enforce rate limits. Below is the complete FastAPI code:
1import aioredis 2import uvicorn 3from fastapi import Depends, FastAPI 4from pydantic import BaseModel 5from fastapi_limiter import FastAPILimiter 6from fastapi_limiter.depends import RateLimiter 7app = FastAPI() 8class PredictionRequest(BaseModel): 9 features: list 10 model_version: str = "default" 11@app.on_event("startup") 12async def startup(): 13 # Connect to Redis - typically you'd get this from environment variables 14 redis = await aioredis.from_url("redis://localhost:6379") 15 await FastAPILimiter.init(redis) 16# Standard prediction endpoint with rate limiting 17@app.post("/predict", dependencies=[Depends(RateLimiter(times=20, seconds=60))]) 18def predict(request: PredictionRequest): 19 # Your ML model inference code goes here 20 result = 0.95 # Placeholder for actual prediction 21 return {"prediction": result, "model_version": request.model_version} 22# More restrictive rate limiting for resource-intensive operations 23@app.post("/predict/batch", dependencies=[Depends(RateLimiter(times=5, seconds=300))]) 24def batch_predict(requests: list[PredictionRequest]): 25 # Resource-intensive batch prediction 26 return {"batch_predictions": [0.95, 0.85, 0.75]} 27if __name__ == "__main__": 28 uvicorn.run("app:app", host="0.0.0.0", port=8000)
Note:
- The FastAPI code for Approach 2 uses
aioredisto connect to Redis. By default, it connects toredis://localhost:6379, which matches the Docker setup. - Here’s the complete FastAPI code with rate limiting: Run the FastAPI Application
- Start the FastAPI server:
1uvicorn app:app --host 0.0.0.0 --port 8000
- The app will connect to the Redis container during startup and use it for rate limiting.
How to Test:
- Test
/predict:
- Test
1for i in {1..21}; do curl -X POST http://localhost:8000/predict -H "Content-Type: application/json" -d '{"features": [1,2,3]}'; echo ""; done
- 429 error after 20 requests.- Test
/predict/batch:
1for i in {1..6}; do curl -X POST http://localhost:8000/predict/batch -H "Content-Type: application/json" -d '[{"features": [1,2,3]}]'; echo ""; done
- 429 error after 5 requests.Approach 3: Rate Limiting with slowapi
When you have complex rate limiting requirements such as different limits for different user tiers, varying limits based on request complexity, or when you need sophisticated rate limiting algorithms beyond simple counters.
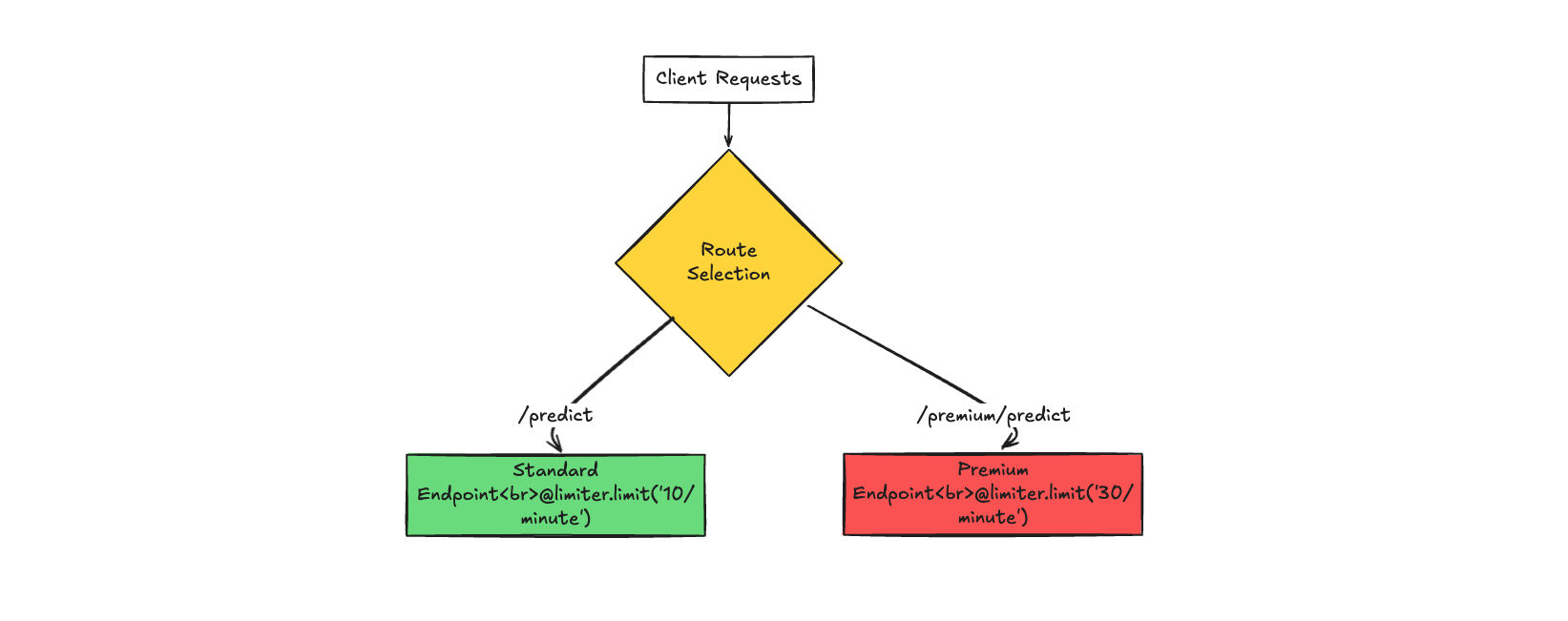
slowapi provides additional features like different rate limit algorithms and customizable responses:
1from fastapi import FastAPI, Request, HTTPException 2from slowapi import Limiter, _rate_limit_exceeded_handler 3from slowapi.util import get_remote_address 4from slowapi.errors import RateLimitExceeded 5from pydantic import BaseModel 6# Initialize Limiter with a default key function 7limiter = Limiter(key_func=get_remote_address) 8app = FastAPI() 9app.state.limiter = limiter 10app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler) 11class ModelInput(BaseModel): 12 data: list 13 parameters: dict = {} 14# Default endpoint with IP-based rate limiting 15@app.post("/predict") 16@limiter.limit("10/minute") 17async def predict(request: Request, input_data: ModelInput): 18 return {"result": "prediction", "status": "success"} 19# Custom key function for premium endpoint 20def get_user_tier(request: Request): 21 return request.headers.get("X-User-Tier", "free") 22# Premium endpoint with tier-based rate limiting 23@app.post("/premium/predict") 24@limiter.limit("30/minute", key_func=get_user_tier) 25async def premium_predict(request: Request, input_data: ModelInput): 26 # Validate that the user is premium 27 tier = get_user_tier(request) 28 if tier != "premium": 29 raise HTTPException(status_code=403, detail="Premium access required") 30 return {"result": "premium prediction", "status": "success"} 31if __name__ == "__main__": 32 import uvicorn 33 uvicorn.run(app, host="0.0.0.0", port=8000)
Notes:
/premium/predictrequiresX-User-Tier: premiumto access; otherwise, it returns a 403 error. How to Run:
- Save as
app.py. - Run:
1uvicorn app:app --host 0.0.0.0 --port 8000
How to Test:
- Free tier on
/predict:
1 for i in {1..11}; do curl -X POST http://localhost:8000/predict -H "Content-Type: application/json" -d '{"data": [1,2,3]}'; echo ""; done
- 429 error after 10 requests.
- Premium tier on
/premium/predict:
1 for i in {1..31}; do curl -X POST http://localhost:8000/premium/predict -H "Content-Type: application/json" -H "X-User-Tier: premium" -d '{"data": [1,2,3]}'; echo ""; done
- 429 error after 30 requests.
- Non-premium user on
/premium/predict:
1 curl -X POST http://localhost:8000/premium/predict -H "Content-Type: application/json" -H "X-User-Tier: free" -d '{"data": [1,2,3]}'
- Expected:
{"detail": "Premium access required"}with a 403 status code.
Pros:
- Feature-rich with multiple rate limiting strategies
- Can define limits based on custom keys
- Supports Redis, Memcached, or in-memory storage
- Good integration with FastAPI Cons:
- Slightly more complex setup
- May have more overhead than simpler solutions
ML-Specific Considerations for Rate Limiting
When implementing rate limiting for ML APIs, consider these specialized factors:
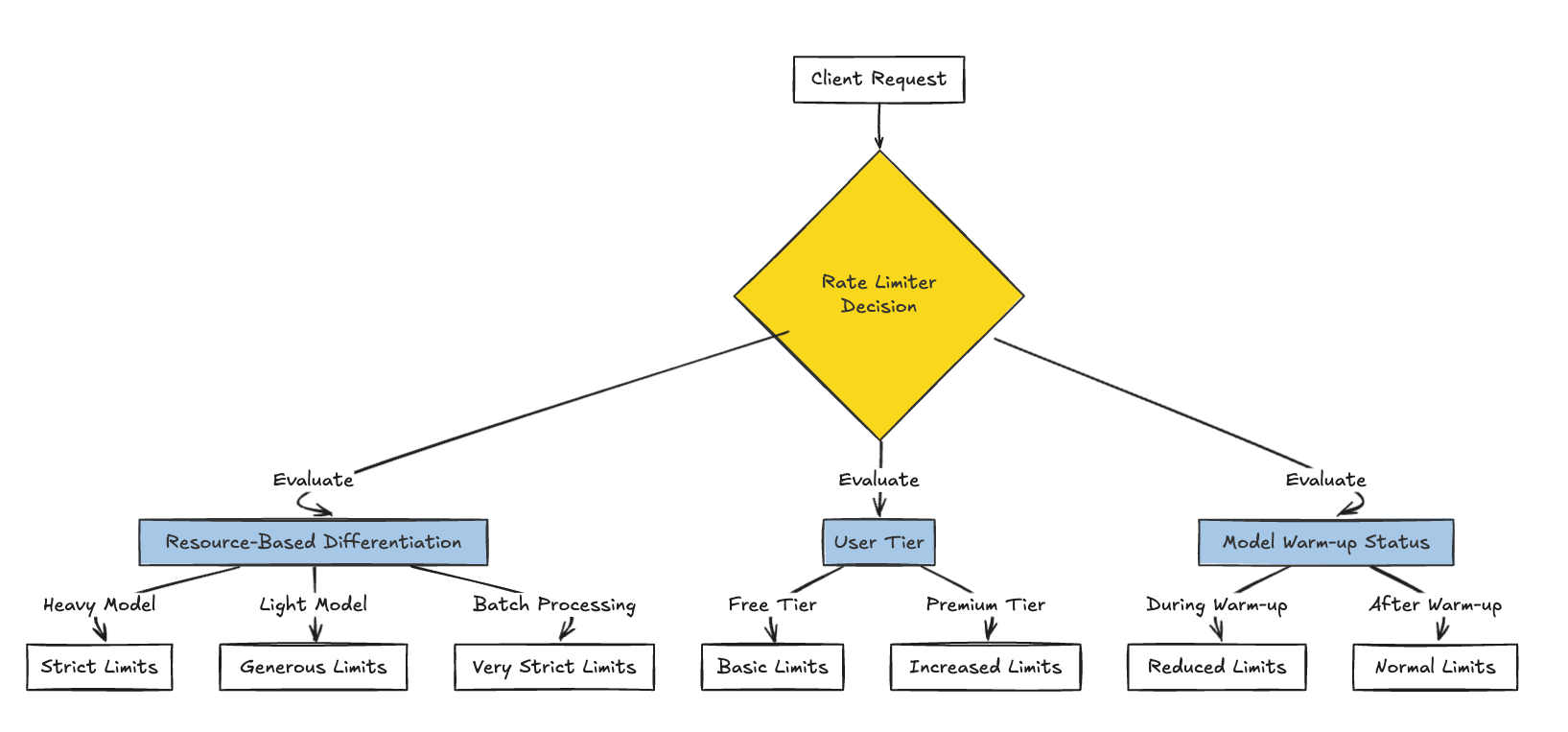
1. Resource-Based Differentiation
Not all ML endpoints consume equal resources. Consider implementing different rate limits based on:
- Computational complexity: More complex models might need stricter limits
- Batch sizes: Large batch requests consume more resources
- Model size: Larger models with more parameters will require more memory Here's how you might implement this:
1# Light model with generous limits 2@app.post("/models/lightweight/predict", 3 dependencies=[Depends(RateLimiter(requests_limit=100, time_window=60))]) 4async def lightweight_predict(data: dict): 5 # Inference with small, fast model 6 return {"prediction": 0.95} 7# Heavy model with stricter limits 8@app.post("/models/heavy/predict", 9 dependencies=[Depends(RateLimiter(requests_limit=10, time_window=60))]) 10async def heavy_predict(data: dict): 11 # Inference with large, resource-intensive model 12 return {"prediction": 0.92} 13# Very restrictive limits for batch processing 14@app.post("/models/batch-process", 15 dependencies=[Depends(RateLimiter(requests_limit=2, time_window=300))]) 16async def batch_process(data: list): 17 # Batch processing logic 18 return {"results": [...]}
2. User Tiers for ML Services
For commercial ML APIs, consider implementing tiered access with different rate limits:
1async def get_user_tier(request: Request): 2 # This could retrieve tier info from a database, token, or header 3 api_key = request.headers.get("X-API-Key") 4 # Lookup tier based on API key (simplified example) 5 if api_key == "premium-user-key": 6 return "premium" 7 return "free" 8class TieredRateLimiter(RateLimiter): 9 async def __call__(self, request: Request): 10 # Override the base rate limits based on user tier 11 tier = await get_user_tier(request) 12 if tier == "premium": 13 self.requests_limit = self.requests_limit * 5 # 5x higher limit for premium 14 return await super().__call__(request) 15# Use the tiered rate limiter 16@app.post("/predict", dependencies=[Depends(TieredRateLimiter(requests_limit=20, time_window=60))]) 17async def predict(data: dict): 18 # Standard limits for free tier (20/minute) 19 # Premium users get 100/minute through the TieredRateLimiter 20 return {"prediction": 0.95}
3. Managing Model Warm-up Periods
ML models often need a "warm-up" period when first loaded. You might implement a dynamic rate limiter that adjusts limits during warm-up:
1class ModelStatus: 2 def __init__(self): 3 self.is_warming_up = True 4 # When the model starts, it's in warm-up mode 5model_status = ModelStatus() 6# After model initialization completes 7@app.on_event("startup") 8async def startup_event(): 9 # Model loading and initialization 10 # ... 11 # After warm-up completes 12 model_status.is_warming_up = False 13class AdaptiveRateLimiter(RateLimiter): 14 async def __call__(self, request: Request): 15 # Reduce limits during warm-up 16 if model_status.is_warming_up: 17 self.requests_limit = max(1, self.requests_limit // 5) # Much lower during warm-up 18 return await super().__call__(request) 19@app.post("/predict", dependencies=[Depends(AdaptiveRateLimiter(requests_limit=50, time_window=60))]) 20async def predict(data: dict): 21 return {"prediction": 0.95}
Monitoring and Debugging Rate Limits
You also need visibility into how your limits are affecting users and system performance. This monitoring approach provides the feedback loop necessary to tune your rate limits over time. Here's a simple approach:
1from fastapi import FastAPI, Request, HTTPException, Depends 2import time 3import logging 4# Configure logging 5logging.basicConfig(level=logging.INFO) 6logger = logging.getLogger("rate_limiter") 7# Initialize counters for metrics 8rate_limit_metrics = { 9 "total_requests": 0, 10 "limited_requests": 0, 11 "endpoints": {} 12} 13class MonitoredRateLimiter(RateLimiter): 14 async def __call__(self, request: Request): 15 endpoint = request.url.path 16 client_ip = request.client.host 17 18 # Update metrics 19 rate_limit_metrics["total_requests"] += 1 20 if endpoint not in rate_limit_metrics["endpoints"]: 21 rate_limit_metrics["endpoints"][endpoint] = { 22 "total": 0, "limited": 0 23 } 24 rate_limit_metrics["endpoints"][endpoint]["total"] += 1 25 26 try: 27 result = await super().__call__(request) 28 return result 29 except HTTPException as e: 30 if e.status_code == 429: # Rate limit exceeded 31 rate_limit_metrics["limited_requests"] += 1 32 rate_limit_metrics["endpoints"][endpoint]["limited"] += 1 33 logger.warning(f"Rate limit exceeded for {client_ip} on {endpoint}") 34 raise 35@app.get("/metrics") 36async def get_metrics(): 37 return rate_limit_metrics
This abstract approach provides basic metrics and logging for rate limiting events, which can be valuable when tuning your limits or diagnosing issues.
Conclusion
Rate limiting is an essential component of production ML APIs, protecting your resources from overuse and ensuring fair service distribution. FastAPI offers several implementation options, from simple in-memory solutions to more robust distributed approaches. For ML engineers, the right approach depends on your deployment scale, infrastructure, and specific requirements. The in-memory approach works well for smaller deployments, while Redis-based solutions offer more robustness for production-grade systems. Remember that effective rate limiting is about finding the right balance—too restrictive, and you limit legitimate use; too permissive, and you risk resource exhaustion or service degradation.